Weka / PDM - Pentaho Data Mining
Data mining concepts
The quantity of data around the world is increasing with no boundaries. Since the volume of data increase, the proportion of people who understand these data is decreasing alarmingly. At data mining, the data are stored in an electronic way and the data searching is automated.
The rampant growth of database during the last years, leads data mining to the forefront of new businesses technology. It is estimated that the quantity of data stored on databases around the world doubles every 20 months. As the machine and data flow, responsible for search engine, becomes ordinary, the opportunity of data mining increases.
Data intelligently analysed are valuable resources. They lead to new discoveries and, in a commercial environment, to competitive advantages and financial gains.
Data Mining solves problems through data analysis.
The extraction of data is defined as a process of discovering data standards. This process must be automated or semi-automated. The standards discovered must be relevant since they have an advantage, normally an economic advantage.
Useful standards allow non-trivial forecasts. There are two extremes to express a standard: as a black box, whose interior is incomprehensible or as a transparent box, whose standard structure is recognised. Both of them are able to forecast, the difference is whether the extracted standards are represented in terms of a recognisable structure, able to be used to inform future decisions. These patterns are known as structural, since they present the structure of decision explicitly. In another words, they may explain something about data.
Machine learning
It is possible to test learning observing the current behaviour and comparing it with past behaviour. In everyday language, several times the word “training” is used to design a stupid way of learning. Nevertheless, learning is different. Learning implies thinking. Learning implies purpose. When something is learned must be intentionally.
Data Mining
Data Mining is a practical subject and involves learning.
We are interested in techniques to find and describe data structural patterns as a tool to help explain data and IT forecasts. Data will take the form of a set of examples, or situations. The output takes the form of forecasting. The output can also include a real description of structure that may be used to classify unknown examples in order to explain decisions. As well as performance, it is useful to offer an explicit representation of acquired knowledge. Essentially, this reflects the learning definitions considered previously: knowledge acquisition and usability.
Several learning techniques look for structural descriptions of what is learned, descriptions that may become very complex and are typically expressed as a set of rules. Because they are understood by people, these descriptions are used to explain what was learned and explain the basis of new predictions.
Experience has shown that on various machine learning applications for data mining, the explicit knowledge of structures and the structural description are as important as the capacity to well perform new examples. People frequently use data mining to acquire knowledge, not only predictions.
Overview and weka functionalities
Weka workbench is a set of state-of-art algorithms for machine learning and pre-processing data tools. It offers extensive support for all the experimental data mining process, including data input preparation, statistical learning systems assessment, data input visualisation and the result of learning. More than a great variability of learning algorithms, it includes a wide variety of pre-processing tools. This toolkit is accessed from a common interface where users can compare different methods and identify which one is suitable in the problem.
Weka was developed at Waikato University, New Zealand. Weka is a bird that does not fly, found only at new Zealand islands. The system is written with Java and it is distributed under GNU General Public License. Any platform can run Weka and it was tested on Linux, Windows, Macintosh and others. It offers a uniform interface to different learning algorithms, methods to pre and post processing and methods to assess the result of learned schemas at any set of data.
Weka provides learning algorithms implementations which can be easily used for your set of data. It also includes tools to a set of transformation data. It is possible to pre-process a set of data, feed it in a learning schema and analyse its performance. Everything can be done without a single line of code.
There are methods for all standard data mining problems: regression, classification, clustering, association, rules mining and attribute selection.
All the algorithms have a relational table in ARFF format as input. It can be read from a file or from a database query.
There are different modes of using Weka. Weka can be used applying a learning method on a set of data and analysing the output in order to understand these data. It is also possible to use what the model learned in order to generate predictions about new instances. Another way is applying different learning and comparing performance in order to choose a forecast.
The learning methods are called classifiers. Many of them have adjustable parameters which are accessed through a properties sheet or object editor. A common assessment method is used to measure the performance of all classifiers.
Real learning systems implementations are the most valuable resource offered by Weka. Secondly, there are data pre-processing tools, called filters. Weka also includes implementations of learning algorithms with association rules, the group of data where the class value is not specified.
How to use Weka
The easiest way to use Weka is through a graphic interface called Explorer. It grants access to all the installations using the menu. For example, it is possible to read a set of data from an ARFF file (or electronic spreadsheet) and build a decision tree with it. But learning decision trees is just the beginning: there are many algorithms to explore. The Explorer interface will help you do just that. It presents options as menus and useful tips when mouse is over an element.
There are others graphical interfaces. The Knowledge Flow Interface allows the creation of configuration for data processing. The main disadvantage of Explorer is that everything is stored at the main memory, i.e., it can be applied on small or medium problems. Nonetheless, Weka has some incremental algorithms that may be used to process big quantity of data. The interface of knowledge flow allows drag and drop of boxes representing learning algorithms and data source around the screen, which permits the desired configuration. In this context, a flow of data is specified when connecting components that represent data source, pre-processing tools, learning algorithms, assessment methods and visualisation modules. Whether the filters and learning algorithms are susceptible at incremental learning, data are loaded and processing in an incremental way.
The third Weka interface, Experimenter, was projected to learn how to answer a practical basic question about application of techniques to classification and regression: Which methods and parameters values work better for the specific problem? At the first time there is no way to answer this question and one of the reasons for Explorer creation was to offer an environment that allows Weka users to compare various learning techniques. Explorer can be used interactively. Behind the interactively interfaces there is the basic functionality of Weka that can be accessed typing textual commands, which allows the access to every system functionality.
What else is possible to do?
An important resource when working with Weka is the on-line documentation automatically generated from source code and concisely reflects its structure.
At the majority of data mining applications, the component of machine learning is just a simple part of a bigger software.
Starting Weka
Weka is available at http://www.cs.waikato.ac.nz/ml/weka link. It is possible to download the installer for an specific platform or a jar file, executed in a normal way whether Java is installed.
 Weka initial screen
Weka initial screen
Suppose you have data and want to create a decision tree from it. At first place, you need to prepare data, so you must open Explorer and load it. Afterwards, you select a method to create the decision tree and interpret output. It is simple to do with a different algorithm or a different method. At Explorer, you can assess the created models using different data, view both models and set of data graphically, including classification error done by these models.
Preparing data
Data are frequently presented in a worksheet or database. However the native method of storage is ARFF format, Explorer can read files from CSV worksheets directly.
Loading data on Explorer
Select “Explorer” from the four graphical user interfaces at the bottom. Six tabs at the top represent the basic operations supported by Explorer. Click on Open file button in order to open an standard dialog able to select a file. Choose the file. Whether the file is in CSV format, the conversion to data file is done automatically. We will use weather.arff file, available at “data” inside Weka.
 Explorer Initial screen
Explorer Initial screen
Once the file is loaded, the screen will present:

This screen presents information about the set of data: there are 14 instances and 5 attributes; the attributes are called outlook, temperature, humidity, windy and play. The first attribute, outlook, is selected as default and there are no lost values, it has three different values, nonexclusive and the real values are sunny, overcast and rainy, occurring five, four and five times respectively.
Outlook attribute is nominal. If you select a numeric attribute, you see minimum and maximum values, average and a pattern in meteorological data reading. In this context the histogram presents the class distribution as a function of this attribute. You can exclude an attribute clicking on its checkbox and using “Remove”. The all button selects all the attributes, “None” selects none and “Edit” button opens an editor to inspect the searching data.
The creation of a decision tree
Click on Classify tab.
First, select the classifier clicking on “Choose” ah the upper left corner, open the trees section at hierarchical menu and find J48.
The menu structure represents the organization of Weka code through modules. Once it is selected, J48 appears at the line by the side of Choose button with default parameters values. If you click on this line, J48 Editor Object classifier opens and you see what the meanings of parameters are, altering values. The explorer usually chooses sensible values. When the classifier is chosen, click on “Start” button. Weka works a short period and produces the output shown at the main panel.

Hierarchical menu
 File output
File output
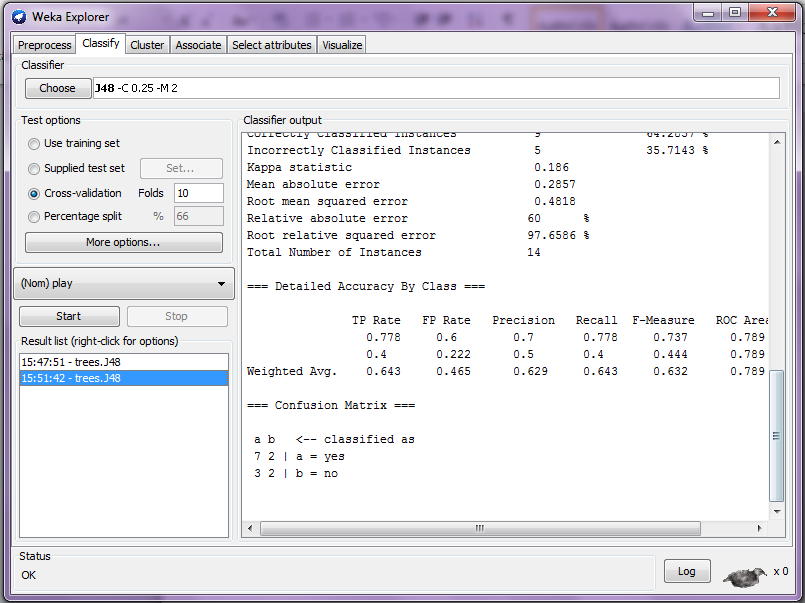
Analysing output
The output is an overview of the dataset and more than ten cross validations were used. If you look at the figure above the Cross-validation box at the left side is selected. A decision tree in a textual mode is presented. The first group is from outlook attribute and, at the second level, the divisions are humidity and windy, respectively. At the tree structure, the colon (:) introduces the class label that has been assigned to a particular leaf, followed by the number of cases that achieves this leaf, expressed as a decimal number, due to the way algorithm uses fractional instances to deal with missing values. If there are some cases incorrectly classified (the is not in this example), its name appears as 2.0/1.0, what means that of two cases that achieved the leaf, one of them was incorrectly classified. Below the tree structure is expressed at the number of leaves, followed by the total number of nodes (tree size).
Afterwards, the output presents the tree performance. In this case, they are obtained using cross-validation laminated with 10 folds. As we can see, more than 30% of the instances (5 of 14) were wrongly classified as cross-validation. This indicates that the results obtained from the training dataset are positive in relation to what can be obtained from an independent test defined using the same source.
As the classification error, the assessment module also generates Kappa statistic, the mean absolute error and the mean squared error of class probability estimative of tree attributes. The Mean squared error is calculated as a similar way, using absolute, not the squared difference.
Real Cases using Data Mining
The Data Mining may be used in all sectors, it is necessary only the desired of analysing data in a better way.
The United States of America uses a real Data Mining application. Since the attacks on the Twin Towers, September, 11th of 2001, the government uses Data Mining to identify possible terrorist activity. Nonetheless, an article written by Eric Lichtblau for the New York Times says that a study realised by scientists and politicians affirms that there is little evidence of the Data Mining efficacy in the search for terrorists due to politic, legal, technological and logistical factors. Nevertheless, the same study assures the efficacy in the use of Data Mining for commercial purposes.
Another example is Walmart. Through Data Mining, married men from 25 to 30 years old were analysed leading to the conclusion of the main purchases: diaper and beer. Therefore, Walmart optimized the location of its shelves: diapers are located next to beers, increasing sales.
The Bank of America also used Data Mining to select clients with the lowest risk of default, so the loans were available only for people inside this group. The bank stopped some important loses.
ARFF files and database connection
ARFF file is the default representation of datasets with unordered and unrelated instances. It is an ASCII text file that describes a list of instances that share a set of attributes. ARFF files have two distinct sections. The first section is the header information, followed by data information.

Example of header at ARFF file
The data of ARFF file is similar to:

Example of ARFF data
Rows that begin with % are comments. Many datasets of learning machines at ARFF format are available at Weka directory in “\data” file.
Attributes declaration
ARFF header section
The ARFF header section contains the declaration of attributes and relations.
Relation declaration
The name of the relation is defined as the first row at ARFF file. The format is: @relation
Attribute declaration
Attribute declaration has the format of an ordered sequence of @attribute declarations. Each attribute on dataset has its own declaration of @attribute that defines the attribute name and data type exclusively. The order that attributes are declared indicates the position of the column in the section of data file.
The format of an @attribute is @attribute
The
Numeric
Integer is treated as numeric
Float is treated as numeric
String
[data
] Relational to various data instances (future use)
Numeric attributes
Numeric attributes can be float or integer
Nominal attributes
Nominal values are defined, presenting a list
Example:
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}.
String attributes
String attributes allows the creation of attributes with arbitrary values which contains arbitrary text values. This is very useful in application mining as we can create a dataset with attributes, followed by Weka filters to manipulate the strings. String attributes are declared as:
@ATTRIBUTE LCC string.
Data attributes
They are declared as @attribute
Relational attributes
They are declared as:
@attribute <name> relational
<further atribute relational>
@end <name>
ARFF data section
The data section of the ARFF file contains the data declaration and real instances Data declaration# Data declaration is an unique line that indicates the beginning of data segments in the file. The format is: @data.
Instance data
Each instance is represented in one line. A percentage (%) signal presents a comment that lasts until the end of the line. Attributes value of each instance are delimited by commas. A comma can be followed by zero or more spaces. The values of the attributes must appear in the order they appear at header section. A missing value is represented by a unique question mark, as in:
@data
4.4,?,1.5,?,Iris-setosa
String values and nominal attributes are case sensitive and anything that contains space or comment delimiter, %, must be quoted. Example:
@relation LCCvsLCSH
@attribute LCC string
@attribute LCSH string
@data
AG5, 'Encyclopedias and dictionaries.;Twentieth century.'
AS262, 'Science -- Soviet Union -- History.'
AE5, 'Encyclopedias and dictionaries.'
AS281, 'Astronomy, Assyro-Babylonian.;Moon -- Phases.'
AS281, 'Astronomy, Assyro-Babylonian.;Moon -- Tables.'
Dates must be specified at data section, using string representation at attribute declaration. For example:
@RELATION Timestamps
@ATTRIBUTE timestamp DATE "yyyy-MM-dd HH:mm:ss"
@DATA
"2001-04-03 12:12:12"
"2001-05-03 12:59:55"
The relational data must be inserted inside double quotes “ “. For example:
MUSK-188,”42,...,30”,1
Some of algorithms implemented by Weka:
Classification methods:
- Induced decision tree
- Learning rules
- Naïve Bayes
- Decision table
- Local weights regression
- Learning based on instances
- Perceptron
- Multilayer perceptron
- Perceptron committee
- SVM
Methods for numerical predictions
- Linear regression
- Model trees generator
- Local weights regression
- Learning based on inatances
- Decision tables
- Multilayers perceptron
Regression algorithm
Regression is the easiest technique to use, but it is probably the less powerful. This model is considered easy because of the existence of an input variable and an output variable (called scatterplot on Excel, or XY Diagram at OpenOffice.org). Clearly, this can become more complex, including dozens of input variables. In fact, all the regression models have the same general pattern. There are some independent variables able to provide a result – a dependent variable. The regression model is used to forecast the result of an unknown dependent variable, since the values of independent variables are known.
Everyone probably used or saw a regression model before and maybe even create a regression model mentally. The example that immediately comes to mind is to calculate the price of a house. The house price (dependent variable) is the result of many independent variables- the house size, the batch size, if there are granite counters in the kitchen, if the bathrooms were renovated, etc. Hence, whether you bought or sold a house, it is probably that you created a regression model to assess the house. The model is created when analysing the neighbourhood and the price of near sold houses (the model), in this context your own house uses this model to produce the expected price. Let’s continue with this regression model based on the price of a house and create some real data to examine.
House size (square feet) Batch size Rooms Granite Is bathroom renovated? Selling price 3529 9191 6 0 0 $205,000 3247 10061 5 1 1 $224,900 4032 10150 5 0 1 $197,900 2397 14156 4 1 0 $189,900 2200 9600 4 0 1` $195,000 3536 19994 6 1 1 $325,000 2983 9365 5 0 1 $230,000
3198 9669 5 1 1 ????
In order to load data on Weka, we need to insert an understandable format, ARFF. The ARFF file used with Weka is presented below.

Creating a regression model with Weka
To create the model, click on Classify tab. The first step is to select the model we want to build, so Weka must know how to work wuth the data and how to create a proper model:
Click on Choose button and expand functions.
Select LinearRegression sheet
This alerts Weka that we want to build a regression model.

Choose the regression model
There is other option called SimpleLinearRegression at the same branching. Do not select it because the simple regression uses only one variable and we have six.
Now that the desired model was chosen, we have to inform Weka where are the data that it must use to build the model. However use data inside ARFF file may be obvious, there are different options, some of them more advanced than the ones we are using. The other three options are “Supplied test set”, where is possible to inform the different dataset to build the model; “Cross-validation”, that allows Weka to create a model based on sub dataset and calculate its mean in order to create a final model; and “Percentage Split”, where Weka uses a percentage subset of data to build a final model. With regression, we can simply choose “Use training set”. It says to Weka that in ordr to build the desired model, we can simply use a dataset in our ARFF file.
Finally, the last step to create a model is to choose the dependent variable (the column we are trying to predict). We know that the column must be the selling price, since it is what we are trying to determine. Below the test options there is a combo box that allows the selection of the dependent variable.
Click on start. The output must be according to the picture below:

Model output
Interpreting regression model
Weka presents the regression model right on the output, as shown in the picture below:

Model output
Below the results, relating the value of the house we want to know the price:

Related output
Nevertheless, Data Mining is not limited to produce a unique number: it includes identifying patterns and rules. It is not strictly used to produce an absolute number, but to create a model able to identify patterns, predict output and take conclusions based on data. Let’s interpret patterns and conclusions offered by the model, besides a unique and strict value for the house:
Granite is not relevant – Weka only uses columns that contribute statistically for the model precision. It discards and ignores columns that do not help the creation of a good model. Hence, this regression model points that the kitchen’s granite does not affect the value of the house.
Bathrooms are important – As we use 0 or 1 for a renovated bathroom, we can use the coefficient of regression model to determine the value of a renovated bathroom in the value of the house. The model points an increase of $42.292 in the house value.
Bigger houses reduce its value – Is Weka pointing that the bigger the house is, the lesser is the selling price? This can be seen by the negative coefficient in front of houseSize variable. Is the model saying that for each foot of the house the price is reduced in $26? It does not make sense. How should we interpret it? This is a good example of trash. The house size, unfortunately, is not an independent variable because it is related to room’s variable, what makes sense since bigger houses have more bedrooms. Therefore, our model is not perfect. But we can fix it. Remember: At Preprocess tab is possible to remove colums from dataset. For your own practice, remove houseSize and create another model. How does it affect the value of the house? Does this model makes sense? (Now the value of my house is $271.894)
Classification algorithm
Classification (also known as classification trees or decision trees) is a Data Mining algorithm that creates a step by step guide to determine output of new data instances. The created tree is exactly this: a tree where each node represents a point where a decision must be taken based on the input and you move along the nodes to the leaf that represents the output. It may seem confusing, but it is very simple.

Classification tree
This simple classification tree is used to answer the question: “Will you learn classification trees?” On each node, answer the question and move along the branching to the leaf that answers yes or no. This model may be used to any unknown data instances and it is possible to predict whether this unknown data instances will learn about classification trees asking only two simple questions.
Apparently, this is the big advantage of classification tree – it does not need too much information about data to create a tree that can be precise and informative. An important concept of classification tree is similar to what we have seen at regression model: the concept of using a “training set” to produce the model. This uses a data set with known output values and uses this dataset to build a model. Hence, when new data, with an unknown output exist, put them inside the model and produce a predictable output. This is what we have seen at regression model. Nonetheless, this type of model continues and it is common to use all the training set, dividing it per two: about 60-80 per cent of data are used on training set and will be used to create the model; the remaining data are used on a test set that will be immediately used to create a model able to test the precision of our model.
This extra stage is relevant for this model because whether we present too much data during the creation of the model, it will be create, nevertheless, it will be valid only for this set. The problem is called super tunning.
It is necessary to use the model to predict future unknown values, not to predict values that we already know. This is the reason why a test set was created. After the model creation, it has to be validated to assure that the precision of the created model is not minimized with the test set. It guarantees the precise prediction of future unknown values. It highlights another important concept for classification trees: cleansing notion. Cleansing involves the removal of branches from classification trees. As the number of attributes in a dataset increases, it is possible to create increasingly complex trees.
False Positive and False negative
Basically, a false positive is a datum instance where the model we created predicts it must be positive, but the real value is negative. On the other hand, a false negative is when a datum instance is predicted as negative but its real value is positive. These errors point that we have mistake inside our model, since it classifies some data incorrectly. However incorrect classifications are expected, the creator of the model defines the acceptable percentage of errors.
WEKA Classification
Load bmw-training.arff (http://www.ibm.com/developerworks/apps/download/index.jsp?contentid=493222&filename=os-weka2-Examples.zip&method=http&locale=pt_BR) data file on Weka using the same stages we described until now. Observation: This file contains only 3000 of 4500 records that concessionaries have. We need to divide records, so some instances can be used to create the model and the remaining can be used to test the model and assure the inexistence of super tunning. After load data, your screen must look like the figure below.

Loaded file
At Classify tab, select nodes and J48 leaf

Choose the tree
Make sure that “Use training set” is selected in order to use the loaded data set to create the model. Click on start and let Weka runs. The output must be similar to:

Model output
- The important numbers that must be focused here are the numbers next to “Correctly Classified Instances” (59,1%) and to “Incorrectly Classified Instances” (40,9%). Other important numbers are at “ROC Area” column at the first line (0,616). Finally, at “Confusion Matrix”, the number of false positives and false negatives are shown. The false positives are 516 and false negatives are 710.
- Based on our accuracy of only 59,1%, it is possible to say from an initial analysis, this is not a good model.
- It is possible to see the tree with right click on the created model (list on “Result Set”), at output list. At pop-up menu, select “Visualize tree”. You will see a classification tree, however, on this example, the visualization is useless. Another way to see the tree is to look to the upper part of the screen, at “Classifier Output”, where the text output presents all the trees, with nodes and leaves.

Tree visualization
There is a final step to validate a classification tree: run a set of tests with the model to assure the model accuracy, assessing whether the test set is not different from the training set. To do so, at “Test options”, select “Supplied test set” button and click on “Set”. Choose bmw-test.arff file, it contains 1500 records, which were not at the training set we used to create the model. At this time, when clicking on Start, Weka will run the test data set on the created model and will notify how the performance was. Below the output is presented.

Model output
Comparing “Correctly Classified Instances” from test set (55,7%) with “Correctly Classified Instances” from training set (59,1%), it is possible to notice that the model won’t fail with unknown data or future data.
Nevertheless, since the model accuracy is bad, classifying only 60% of data records, we conclude that as this is only a little bit over 50%, we can achieve it by guessing values randomly. This is totally true and leads to an important point: sometimes, to apply data mining algorithms will produce bad models.
The obtained results on Weka indicate that a classification tree is not a model that should be selected here. The created model does not say anything and, whether it would be used, it could create poor decisions and waste money.
Clustering algorithm
Cluster storage allows user to group data in order to define patterns from data. The cluster storage has its advantages when data set is defined and the general pattern needs to be defined from data. It is possible to create a specific number of groups, depending of your business needs.
A decisive benefit of cluster storage about classification is that each attribute on data set will be used to analyse data.
A great disadvantage of using cluster storage is that the user requires knowing, in advance, how many groups he would like to create. To a user without any real knowledge about his data, it can be difficult and takes various stages using “trial and error” to define the ideal number of groups to be created.
Nevertheless, to the medium user, the cluster storage can be the most useful data mining method to be used. It can take all the data set and transform in groups, which is possible to take fast conclusions. The math behind this method is relatively complex and confusing.
That is why we enjoy all Weka advantages.
Math overview
This must be considered a quick, not detailed, overview of math and the algorithm used at cluster storage:
- Each attribute in this data set must be normalised. Each value is divided by the difference between the highest value and the lowest on data set for this attribute. For instance, if the attribute is age and the highest value is 72 and the lowest is 16, the age of 32 must be normalised to 0,5714.
- Once the number of desired clusters is presented, select, randomly, the number of samples from the data set that can be used as our initial test. For example, if you wish to have three clusters, you will select, randomly, three rows of data from the data set.
- Calculate the distance of each sample to the centre of the cluster (or randomly selected row of data), using the method of least squares.
- Assign each row to a cluster, based on the minimal distance to each centre of the cluster.
- Calculate centroid. This is the mean of each column of data using only the members of each cluster.
- Calculate the distance of each data sample until the created centroids. If clusters and clusters members do not change, you finished and clusters are created. In case of changing, it is necessary to start again, going back to stage 3 and continuing until the clusters do not change.
Weka Data set
The data set that we will use as cluster storage example will be focused on BMW imaginary concessionaire. The concessionaire monitored how many people enter the exhibition and the store, which cars were they looking at and how often they, finally, bought.
They expect to mine data by finding patterns and using cluster to define if certain behaviour appeared among the clients. There are 100 columns of data at this sample and each column describes the stages where the clients were with BMW experience. Column with 1, they achieved the stage or looked at the car; column with 0 they did not achieve this stage.
Below there are ARFF data that will be used with WEKA:

Model data
Cluster storage at Weka
Load bmw-browsers.arff file at Weka using the same stages as we used to load data on Preprocess tab.
Loaded file
The creation of clusters is expected with this data set, so, instead of clicking on Classify tab, click on Cluster tab. Click on Choose and select SimpleKMeans from the options that appear.
Finally, it is necessary to adjust the cluster algorithm’s attributes by clicking on SimpleKMeans. The only algorithm attribute that the adjustment is interesting is numClusters field, that presents how many clusters we wish to create (it is necessary to know this before the beginning). For while, change the default value from 2 to 5, but remember these stages in case of adjusting the number of created clusters. At this moment, your WEKA Explorer must look like the picture below. Click on OK to accept these values.

Weka Explorer
At this moment, the cluster storage algorithm is ready to run. Remember that 100 rows of data with 5 data clusters would take, probably, some hours of calculation on a spread sheet, but WEKA can answer in less than one second. Its output must be like:

Model output
The output is presenting how each cluster is linked: “1” means that each one on that cluster shares the same value -1; “0” indicates that each one on that cluster has a value of zero for that attribute. The numbers are the mean of everyone in the cluster. Each cluster shows a type of our client’s behaviour, from where we can take some conclusions.
- Cluster 0 – It is a group where clients walk on the store, looking at cars, but do not buy anything.
- Cluster 1 – it is a group that head to M5, ignoring Z4 and 3-series cars. Nevertheless they do not have a high purchase rate – only 52%. This is a potential problems and could be focused by the concessionaire, maybe sending more salesperson to M5 section.
- Cluster 2 – It is a group so small that we can name as “throw out”, since they are not statistically relevant and we cannot take any good decision from their behaviour (Sometimes, it happens with clusters and may indicate that is necessary to minimize the number of clusters)
- Cluster 3 – It is a group that always buy a car and financing it. Here the data is interesting: They walk on the parking lot, looking at cars, afterwards they use the searching engine on the computer available at the concessionaire. Finally they tend to buy M5 or Z4 (but never 3-series). This cluster says that the concessionaire must consider becoming computers noticeable at the parking lot and, maybe becoming M5 and Z4 noticeable in the searching results. When a client decides to buy a vehicle it always should present a financing and finish the purchase.
- Cluster 4 – It is a group that always look to 3-series but never to M5, more expensive. They enter the exhibition, choose do not walk on the parking lot and tend to ignore the computers. While 50% achieves financing stage, only 32% finalise the transaction. The concessionaire can conclude that these clients that expect to buy their first BMW know exactly which car they want (the 3-series model) and expect to have financial conditions to afford it. The concessionaire could, possibly, increase sales for this group, relaxing financing patterns or reducing 3-series price.
Another interesting way to analyse data inside these clusters is visually inspect them. To do so, right click on Result List section at Cluster tab. One of the options of this pop-up menu is Visualize Cluster Assignments. A window will appear to let you play with results, visualizing it. In this example, change x axis to be M5 (Num), Y axis to be Purchase (Num) and colour to be Cluster (Nom). It will show, graphically, how the clusters are grouped based on who looked at M5 and who bought it. Increase “Jitter” to three quarters of the limit, this will artificially spread the points to allow an easy analysis. The visual results match the conclusions we take from output results. It is possible to see at X=1, Y=1 (people who looked at M5 and bought it) that the only clusters represented here are 1 and 3. We also can notice that the only clusters at X=0,Y=0 are 4 and 0.

Cluster visualization
Association algorithm
Association creates rules able to describe the most relevant data patterns. Rules are formed of precedents and consequents, i.e, the rule contains at the precedent a sub set of attributes and its values and at the consequent a sub set of attributes from the precedent. Rules have different uses, among them the discovery of behaviour patterns, marketing applications and new products development.
Creating a classification model with Weka
We will use Apriori algorithm from the suite to exemplify the association application at Weka. The data set we will use will be supermarket.arff (available at weka/data). This data set describes a set of client’s purchases in a supermarket. Each instance is a purchase and when a client buys a certain attribute, its value will be ‘t’. The set is formed by 217 attributes and 4627 instances. To use Apriori, firstly we need to load supermarket.arff. After the file is open, we head to Associate tab. Besides selection, it is possible to note some rules.
The output is the best 10 rules, number that can be changed on algorithm settings.

Model output
The confidence means the percentage of occurrence of the rules. Confidence is calculated from a portion of examples that fall within precedent and that also consequent. Output:
- If the client bought cookies, frozen foods, fruits and the total was expensive, it means he bought bread and cake. 92% of confidence.
- If the client bought kitchen utensils, fruits and the total was expensive, it means he bought bread and cake. 92% of confidence.
- If the client bought kitchen utensils, frozen food, fruits and the total was expensive; it means he bought bread and cake. 92% of confidence.
- If the client bought cookies, fruits, vegetables and the total was expensive, it means he bought bread and cake. 92% of confidence.
- If the client bought snacks, fruits and the total was expensive, it means he bought bread and cake. 91% of confidence.
- If the client bought cookies, frozen foods, vegetables and the total was expensive, it means he bought bread and cake. 91% of confidence.
- If the client bought kitchen utensils, cookies, vegetables and the total was expensive, it means he bought bread and cake. 91% of confidence.
- If the client bought cookies, fruits and the total was expensive, it means he bought bread and cake. 91% of confidence.
- If the client bought frozen foods, fruits, VEGETABLES and the total was expensive, it means he bought bread and cake. 91% of confidence.
- If the client bought frozen foods, fruits and the total was expensive, it means he bought bread and cake. 91% of confidence.
Interpreting results statistically
The results interpretation consists in assess the knowledge extracted from databases, identify patterns and interpret them, changing to knowledge that support decisions.
The process result must be understandable to decision-takers who are responsible for validating the acquired knowledge, verifying if the results are applicable for new patterns discovery, suggestions for attributes improvement and refinement of knowledge. Therefore, the importance of group work – analyst and user – is observed in order to refine the results and become it relevant, achieving the desired confidence.
ARFF file generation thorugh Pentaho Integration
It is necessary to insert ARFF Output step on PDI. Access Pentaho Wiki and see all Pentaho Data Integration- Kettle: http://wiki.pentaho.com/display/EAI/List+of+Available+Pentaho+Data+Integration+Plug-Ins
Download option according to your Pentaho Data Integration (PDI) – Kettle version of ARFF Output, at Plugins – Transformation Steps list.
Unzip the file and copy “ArffOutputDeploy” folder to PDI ../plugins/steps installation directory.
It is also necessary copy weka.jar file, on Weka Data Mining installation directory to PDI ../lib folder.
Restart PDI and access step option. You will see ARRF plugin.

ARFF Output Step
Using ARFF Output Plugin on PDI


ARFF Output Step Editor
The dialog box presents a text field that can be used to name step separators and three tabs that can be used to configure step .
- Choose a name for ARFF file
- Choose a relation name (something short to describe data relation)

ARFF Output Step Editor
- Choose a format to be used (Unix or DOS)
- Choose an encoding to use

Arff Output Step Editor
The mapping between the type of Kettle input field and the type of ARFF attributes that will be recorded on file is shown on Fields tab. Any problem here can be corrected through data modification. ARFF output stage maps Kettle String type to ARFF nominal, number and integer to numeric, and date to date. All the formatting and accuracy of data is respected. At this tab, you can also specify that each row on ARFF file must be specified using the Kettle input. If this option will not be selected, as default, each instance on ARFF file receives weight 1. Default ARFF format can support weights 3.5.8 and so on.
- Comment mapping between type fields of Kettle and ARFF. Correct any problem.
File format (Unix or DOS) and character codification can be select at Content tab. The default format is DOS and the default characters configuration depends on the platform.